【Windows編】FIM AI:回復期を想定したFIM予測AIアプリの使い方(Python・Django・LightGBM)
【更新状況など】
2021年7月25日(日)
4 機械学習・人工知能のリハビリテーション応用:4.1 機械学習とFIM予測関連研究の動向は?
2021年7月に、日本人の著者などにより発表された、研究論文の情報を追記しました。
2020年8月14日(金)
チュートリアル動画を公開しました。
人工知能・機械学習のリハビリテーション応用に関心のある方の参考になることがありましたら幸いです。
2020年8月12日(水)
動画の録画が終了しました。今後編集予定です。
現時点で記事に掲載している「環境設定」や「各種コード」を活用することでアプリ起動〜オリジナルデータセットでAIに学習させることが可能です。
2020年8月11日(火)
SQLite3のダウンロード・インストールの情報を追記しました。詳しい解説は動画で実施予定です。
2020年8月10日(月)
「fim_db.sqlite3」のファイル出力・インポート関連の情報を追記・更新しました。
難しい・・・?FIM予測AIアプリをWindowsのローカル環境で起動する方法
理学療法士の有資格を保有されているAIエンジニアの開発者の方が、2020年に公開してくださった
・回復期病院を想定したFIM予測AIアプリ
tomoyasu-sano/portfolio_predict_fim | GitHub
https://github.com/tomoyasu-sano/portfolio_predict_fim
開発者の方によるデモ | FIM予測AI
* 2023年1月時点では開発者の方によるデモがなくなっているようでした
をご存知の理学療法士・作業療法士・言語聴覚士の臨床家や研究者の方もいるのではないかと思いますが
「 開発者の方にコンタクトする前に、試しに、自分でも動かしてみたいが、コードの使い方が意味不明・・・ 」
と、頭を抱えている方も多いのではないかと思います。
そこで、このページでは、リハビリ専門家の方の情報収集の利便性を考え、上記のFIM予測AIアプリのGitHubコードを使う方法をまとめておきます。
コードを実行する方法は、様々な方法があるのではないかと思いますが
・Windows 10のローカル環境で起動する(使用する)
方法についてまとめておきます。
ローカル環境で起動方法の一例ではありますが、病院や施設などでAIアプリに触れるきっかけになることがありましたら幸いです。
Functional Independence Measure(FIM:機能的自立度評価法)のように、定期的に実施する評価結果を有効活用する方法について、頭を悩ませている方もいるのではないかと思います。
今回、使い方をまとめさせていただいたFIM予測AIアプリのような仕組みを試せることで、日々蓄積されるデータの使い方に関心を持たれる方も増えてくるのではないかと思います。
また、感の鋭い方は
「 今回の技術を応用することで、もしかして、xxxの予測もできるのでは? 」
と感じるのではないかと思います。リハビリテーション領域のAI応用・・・・
今後が楽しみです。
【手順の概略と動画解説】
:ローカル環境でAIアプリの起動・オリジナルデータセットでAIに学習させる方法
【動画で使い方解説】
FIM予測AIアプリ – 機械学習のリハビリテーション応用(Python・Django・LightGBM)

視聴時間:46分39秒
記事の内容だけでは手順をイメージしにくい場合などに、適宜、該当箇所の動画をご視聴ください。
画質を最高(1080p60 HD)にすると見やすくなるようでした。
* 動画で表示されている記事の内容は、録画時の状態です。訂正など最新の情報は、この記事ページを参照ください。
* 記事内の説明の訂正箇所(修正済み)がいくらかありますが、動画と同様に手順・コード実行をしていただければ問題ないかと思います。
【Windows 10のローカル環境で起動する(使用する)】
・開発環境の構築 0:10〜
- Visual Studio Codeのインストール・日本語化 0:34
- FIM予測AIのダウンロード GitHub 2:46
- Pythonのインストール 4:11
- PostgreSQLのインストール 6:28
(動画の訂正)
記事内の説明の「C:¥Program Files¥PostgreSQL」× → 「C:¥Program Files¥PostgreSQL¥12」○
(動画の訂正)
記事内の説明の「C:¥Program Files¥PostgreSQL¥bin」× → 「C:¥Program Files¥PostgreSQL¥12¥bin」○
- SQLite3のインストール 12:00
・仮想環境の構築:djangoai 16:24
・仮想環境に入る 17:33
・pip install -r requirements.txt;各種インストール 18:23
・settings.pyの設定:シークレットキー・データベース 19:25
・python manage.py migrate:データベースに反映 23:01
・python manage.py runserver:Djangoの立ち上げ・FIM予測AIの起動 23:42
・PostgreSQLのデータベースに保存された入力データの確認方法 27:21
【オリジナルデータセットでFIM予測AIアプリに学習をさせる】
・fim_db.sqlite3:SQLLite3 学習に使ったデータセットの確認・csv出力・新規データセット作成・csv入力 31:58
- fim_db.sqlite3のデータをcsv形式へ 32:06
(動画の訂正)
記事内の説明の「output.cvs」× → 「output.csv」○
- 学習データの編集 35:12
- FIMデータの入力項目などについて 37:49
(動画の訂正)
記事内の説明の「memoru」× → 「memory」○
- オリジナルデータをfim_db.sqlite3へ 39:21
・オリジナルデータでAIを学習させる 42:16
- python create_db_pickle.py:data内にdf.pickleができる
- python train.py:オリジナルデータセットで学習の実行
詳細:ローカル環境でAIアプリの起動・オリジナルデータセットでAIに学習させる方法
Windows 10のローカル環境で起動する(使用する)
* 基本的に、コードは半角英数で入力していきます。
開発環境の構築
始めに、開発環境を構築するために以下をダウンロード・インストールします。
① Vidual Studio Code(VSCode)のダウンロード・インストール
:コードエディター
Vidual Studio Code
https://code.visualstudio.com/
* インストール時の設定「追加タスクの選択」で
「□ デスクトップ上でアイコンを作成する」
「□ PATHへの追加(再起動後に使用可能)」
にチェックを入れています。
* 拡張機能の設定で日本語化できます。
拡張機能で「Japanese Language Pack for Visual Studio Code ms-ceintl.vscode-language-pack-ja」をインストール後、Vidual Studio Codeを再起動すると日本語化されます。
② GitHub – FIM予測AI(portfolio_predict_fim-master)のコードのダウンロード
tomoyasu-sano/portfolio_predict_fim | GitHub
https://github.com/tomoyasu-sano/portfolio_predict_fim
* 「portfolio_predict_fim-master」のフォルダをダウンロード後、Vidual Studio Codeでフォルダを開きます。
* 今回は、デスクトップ画面上に「portfolio_predict_fim-master」のフォルダを置いた状態で解説していきます。
③ Python 3.7.3のダウンロード・インストール
:プログラミング言語
Python 3.7.3・64bitのWindowsの場合は「Windows x86-64 executable installer」を、32bitのWindowsの場合は「「Windows x86 executable installer」をダウンロード・インストール
https://www.python.org/downloads/release/python-373/
インストールの際に
「□ Add Python 3.7 to PATH」
をチェックした状態でPythonをインストールします。環境変数(パス)の設定を自動的にしてくれます。環境変数を設定しない場合は、自分で設定する必要があります。
インストール後にVisual Studio Codeのターミナルで以下のコードを実行します。
実行コード:(コードを入力後に「enter」キーを押します)
python --version
コードを実行し、バージョンの確認した際に「Python 3.7.3」と表示されることを確認します。
* 反応しない場合は、Vidual Studio Codeを再起動後に実施してみてください。
④ PostgreSQLのダウンロード・インストール
:データベース
PostgreSQL Database Download
https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
* 64bitのWindowsパソコンの場合は、「Windows x86-64」を、32bitのWindowsパソコンの場合は、「Windows x86-32」をダウンロード・インストールします。
インストール時に、
・PostgreSQL用のパスワード
・インストール先の設定
(今回はインストール先を(例)「C:¥Program Files¥PostgreSQL¥12」内に設定しているので、環境変数を設定する際には「C:¥Program Files¥PostgreSQL¥12¥bin」を指定しています)
・ポート番号の設定
(今回は、デフォルト設定の「5432」を設定)
などの設定があります。
また、インストール完了後に表示される
「Setup has finished installing PostgreSQL on your computer.Launch Stack Builder at exit?
□ Stack Builder maybe used to download and install additional tools, drivers and applications to complement your PostgreSQL instakkation.」
のチェックを外した状態で「Finish」をクリックします。
インストール後に、環境変数(パス)の設定を行います。そのため、「インストール先」を記録しておくと、環境変数設定の際に慌てなくて済むのではないかと思います。環境変数を設定することで、PostgreSQL関連コードを入力するとターミナルで反応するようになります。
【PostgreSQLの環境変数の設定方法】
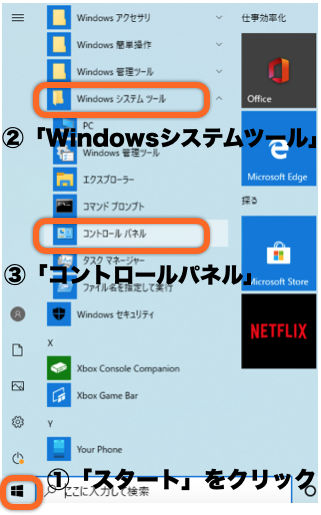
以下の手順で、環境変数の設定画面を開きます。
スタート(Windowsマーク) > Windowsシステムツール > コントロールパネル > システムとセキュリティ > システム > システムの詳細設定 > システムのプロパティ – 環境変数
スタート > Windowsシステムツール > コントロールパネルの開き方
環境変数の設定画面で、以下の手順を実施します。
① システム環境変数(S)内の「Path」を選択
② 編集をクリック
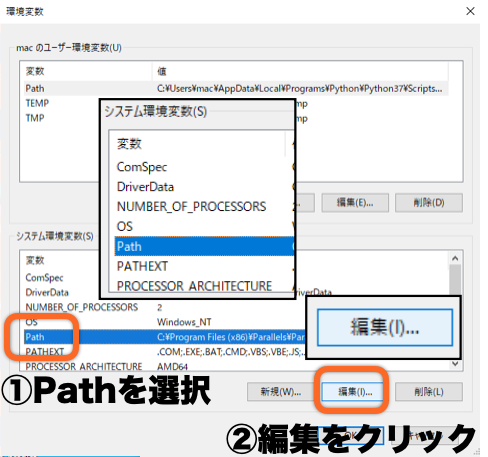
環境変数名の編集画面で、以下の手順を実施します。
① 「新規(N)をクリック」
② 新たな環境変数が入力できるようになります。
(この状態で、PostgreSQLのインストール時に設定したPostgreSQLのインストール場所(例)「C:¥Program Files¥PostgreSQL¥12」を参考にして(例)「C:¥Program Files¥PostgreSQL¥12¥bin」と直接入力することもできます)
③ 「参照(B)をクリック」
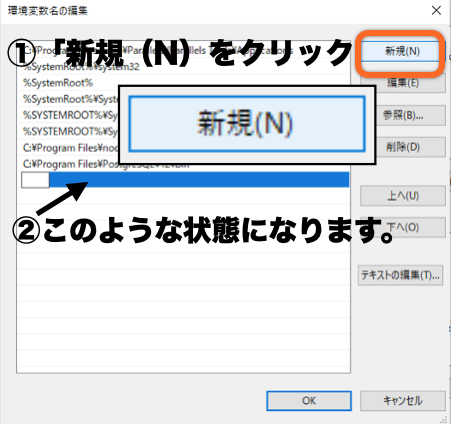
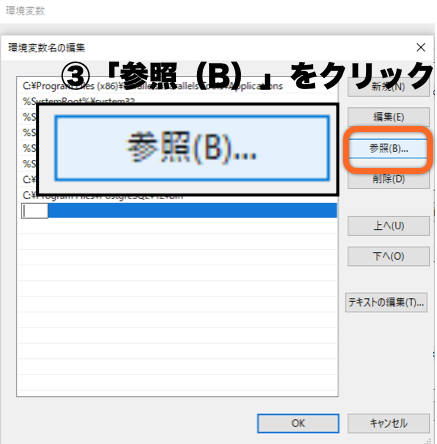
フォルダーの参照で、以下の手順でPostgreSQL内の「bin」を探します。
(PostgreSQLインストール時の設定時に指定した場所に、PostgreSQLがあると思います)
PC > ローカルディスク > Programm Files > PostgreSQL > 12 > bin
「bin」を選択した状態で、「OK」をクリックします。
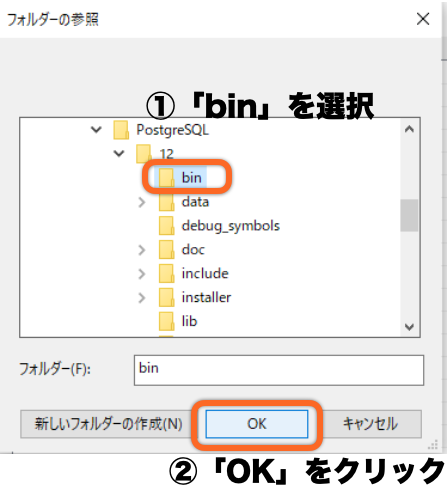
環境変数名が新たに追加されたことを確認し、「OK」をクリックします。
*今回は、(例)「C:¥Program Files¥PostgreSQL¥12¥bin」の追加
PostgreSQLのバージョン確認をしてみます。
インストール後、環境変数を設定したらVisual Studio Codeのターミナルで以下のコードを実行します。
実行コード:(コードを入力後に「enter」キーを押します)
psql --version
「psql (PostgreSQL) 〜」の出力があれば、環境変数の設定は成功です。
* 反応しない場合は、Vidual Studio Codeを再起動後に実施してみてください。
⑤ SQLite3のダウンロード・インストール
:データベース
SQLite Download Page
:https://www.sqlite.org/download.html
64bitのWindowsの場合は、Precompiled Binaries for Windowsのところの「sqlite-tools-win32-x86-〜.zip」「sqlite-dll-win64-x64-〜.zip」をダウンロードします。
32bitのWindowsの場合は、Precompiled Binaries for Windowsのところの「sqlite-tools-win32-x86-〜.zip」「sqlite-dll-win32-x86-〜.zip」をダウンロードします。
その後、任意の場所に「sqlite」というフォルダを作成し、上記の2つの圧縮ファイルを解凍後に出てきたファイルを「sqlite」のフォルダの中に全て入れます。
その後、上述のPostgreSQLの手順と同じように環境変数(パス)を設定します。環境変数の設定の際は「sqlite」のフォルダを選択します。
設定が完了したら、SQLiteのバージョン確認をしてみます。
Visual Studio Codeのターミナルで以下のコードを実行します。
実行コード:(コードを入力後に「enter」キーを押します)
sqlite3 --version
バージョンの出力があれば、環境変数の設定は成功です。
* 反応しない場合は、Vidual Studio Codeを再起動後に実施してみてください。
* 手順の詳細は、動画の「SQLite3のインストール 12:00」を参照ください。
仮想環境の構築:djangoai
「djangoai」という名前の仮想環境を作成します。(今回は、portfolio_predict_fim-masterのフォルダの直下に作成します)
仮想環境のイメージとしては、Windowsのパソコンの中に、何もアプリの入っていない新しいWindowsを入れるようなイメージのようです。
この仮想環境の中に、FIM予測AIアプリを使うために必要なライブラリなどをインストールしていきます。
①「djangoai」という名前の仮想環境の作成。
Visual Studio Codeで、「portfolio_predict_fim-master」のフォルダを開いた状態で、「新しいターミナル」(ターミナル > 新しいターミナル)を表示させ、ターミナルで以下のコードを実行します。
実行コード:(コードを入力後に「enter」キーを押します)
python -m venv djangoai
② 仮想環境に入ります(仮想環境を起動します)。
実行コード:(コードを入力後に「enter」キーを押します)
djangoai\Scripts\activate
* 上記のコードをコピーしてターミナルにペーストすると「¥」の部分が「バックスラッシュ」に変換されると思います。
* 上記のコードをコピー&ペーストするか、そのままターミナルに「activate」(portfolio_predict_fim-master > djangoai > bin > activate)というファイルをドラッグ&ドロップする方法でもできます。
「djangoai¥Scripts¥activate」(キーボード入力の¥)では上手く反応しませんでした。
成功するとターミナルの表示が
(djangoai)〜
になります。
pip install -r requirements.txt:各種インストール
「requirements.txt」(portfolio_predict_fim-master > requirements.txt)を使って、必要なライブラリなどを仮想環境「djangoai」にインストールしていきます。実行時にはインターネットの接続が必要です。
実行コード:(コードを入力後に「enter」キーを押します)
pip install -r requirements.txt
* Python 3.7.3であれば成功するはずです。
settings.pyの設定:シークレットキー・データベース
「settings.py」(portfolio_predict_fim-master > predict_fim_pj > settings.py)を編集・変更・追記していきます。
① シークレットキーを設定します。
追加コード:(settings.pyの25行目前後)
SECRET_KEY = 'hgygjkgugkbknl'
* レンタルサーバーなどでウェブアプリを外部に公開する場合は、setting.pyにシークレットキーの情報を直接入力することは推奨されていないようです。今回はローカル環境のためシークレットキーを直接入力する方法で実施します。
サンプルのシークレットキーの「'hgygjkgugkbknl’」は半角英数で任意のキーを入力してください。
② デバックの設定を変更します。
変更コード:(settings.pyの29行目前後)
DEBUG = True
* レンタルサーバーなどでウェブアプリを外部に公開する場合は「DEBUG = False」が推奨されているようです。現状のコードでローカル環境で起動する場合に「DEBUG = False」ではエラーとなるため、今回は「DEBUG = True」の設定にします。ウェブアプリにエラーがある場合に、ウェブアプリのページにエラーの詳細情報が表示されるようになります。
③ 「NAME」「USER」「PASSWORD」「HOST」の設定をします。以下のように入力します。
(settings.pyの81行目前後)
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.postgresql_psycopg2',
'NAME': 'postgres',
'USER': 'postgres',
'PASSWORD': '*****',
'HOST': 'localhost',
'PORT': '',
}
}
* 「'*****’」のところは、PostgreSQLをインストールした際に設定したパスワードを、半角英数で入力してください。
上記の
・シークレットキーの設定
・デバックの設定
・「NAME」「USER」「PASSWORD」「HOST」の設定
ができたら
・保存(メニューの ファイル > 保存)
します。保存するとコードを実行する際に、設定が反映されます。
python manage.py migrate:データベースに反映
マイグレーションファイルの設定内容をデータベースに反映させます。
Visual Studio Codeのターミナルで以下のコードを実行します。
実行コード:(コードを入力後に「enter」キーを押します)
python manage.py migrate
python manage.py runserver:Djangoの立ち上げ FIM予測AIの起動
Djangoの開発サーバーを立ち上げ、FIM予測AIアプリを起動します。
Visual Studio Codeのターミナルで以下のコードを実行します。
実行コード:(コードを入力後に「enter」キーを押します)
python manage.py runserver
成功すると
http://127.0.0.1:8000/predict/
のページでFIM予測AIアプリを試すことができます。
一度、ここまでの手順ができれば、再度起動したい場合には、
① Visual Studio Codeを起動
② 設定済みの「portfolio_predict_fim-master」のフォルダを開く
③ 仮想環境に入る(仮想環境を起動する)
実行コード:
djangoai\Scripts\activate
* 上記のコードをコピー&ペーストするか、そのままターミナルに「activate」(portfolio_predict_fim-master > djangoai > bin > activate)というファイルをドラッグ&ドロップする方法でもできます。
④ Djangoの開発サーバーを立ち上げ、FIM予測AIアプリを起動
実行コード:
python manage.py runserver
の手順のみで
http://127.0.0.1:8000/predict/
のページで、FIM予測AIアプリを使用できます。
次に、FIM予測AIアプリに入力されたデータを確認する方法を解説します。
PostgreSQLのデータベースに保存された入力データの確認方法
FIM予測AIアプリに入力したデータは、PostgreSQL内にデータが残るようです。
(今回の方法では、「postgres」内の「predict_fim_app_predict_fim_app」で情報を確認できます。)
【PostgreSQLのデータベースに保存された入力データの確認方法】
① まずは、データベースへログインします。
Visual Studio Codeのターミナルで以下のコードを実行します。
実行コード:(コードを入力後に「enter」キーを押します)
psql -U postgres
*パスワードが求められます。入力後(特に何も表示されません)、「enter」キーを押します。
② テーブル一覧の表示をします。
実行コード:(コードを入力後に「enter」キーを押します)
¥dt;
* predict_fim_app_predict_fim_app のテーブルができているのが確認できます。
③ 特定のテーブル(predict_fim_app_predict_fim_app)内のデータの一覧を確認します。
実行コード:(コードを入力後に「enter」キーを押します)
select * from predict_fim_app_predict_fim_app;
④ csv出力もできます。
* csv(Comma Separated Values:カンマ区切りファイル形式)
実行コード:(コードを入力後に「enter」キーを押します)
¥COPY predict_fim_app_predict_fim_app To '¥c:¥Users¥Windowsのユーザー名¥Desktop¥portfolio_predict_fim-master¥任意の名前.csv' WITH CSV DELIMITER ',';
* 「¥c:¥Users¥Windowsのユーザー名¥Desktop¥portfolio_predict_fim-master」のところは、csvファイルを出力させたい場所を入力します。今回は、直接フォルダをドラッグ&ドロップして場所を指定しています。「任意の名前.csv」は半角英数で名前をつけてください。(例「input_data.csv」)出力されるcsvファイルの名前の設定です。
* 動画では最後のコード「DELIMITER ‘,’;」でエラーとなっています。上記のコードは「DELIMITER ',’;」と修正しておきました。
それでもエラーが出る場合は、シングルクォーテーション(’)はご自身で入力してみてください。
PostgreSQLのコマンドを終了するには以下のコードを実行します。
実行コード:(コードを入力後に「enter」キーを押します)
¥q
次は、オリジナルFIMデータで(オリジナルデータセット)で、FIM予測AIアプリを学習させる方法を解説します。
オリジナルデータセットでAIに学習をさせる方法
fim_db.sqlite3のデータをcsv形式のファイルに書き出す
データベースから、csvに書き出すために以下の手順を順番に実施します。
Visual Studio Codeで、「portfolio_predict_fim-master」のフォルダを開いた状態で、「新しいターミナル」(ターミナル > 新しいターミナル)を表示させ、ターミナルで以下のコードを実行します。
① fim_db.sqlite3に入ります。
実行コード:(コードを入力後に「enter」キーを押します)
sqlite3 fim_db.sqlite3
*「fim_db.sqlite3」に学習用(済み)のFIMデータ(デフォルトでは、テスト用にダミーデータが入れてあるようです)があります。
② テーブル一覧を表示します。
実行コード:(コードを入力後に「enter」キーを押します)
.tables
「fim_data」というテーブルが出力されると思います。
③ ヘッダー表示をONにします。ヘッダーとしてカラム名(idなど)が表示されるようになります。
実行コード:(コードを入力後に「enter」キーを押します)
.headers on
④ csvモードにします。
実行コード:(コードを入力後に「enter」キーを押します)
.mode csv
⑤ 結果の出力先をファイルにします。今回は「output.csv」というファイル名を指定しています。
実行コード:(コードを入力後に「enter」キーを押します)
.output output.csv
「portfolio_predict_fim-master」のフォルダ内に空の「output.csv」という名前のファイルが作成されます。
⑥ 「fim_data」内のデータを「output.csv」に出力します。
実行コード:(コードを入力後に「enter」キーを押します)
select * from fim_data;
実行後に「output.csv」を確認すると、「fim_data」のデータが表示されます。
⑦ データベース操作を終了します。
実行コード:(コードを入力後に「enter」キーを押します)
.exit
これで 「output.csv」というファイルが出力されます。Excelなどで編集できます。
(Windows用のExcelを入れていないので動画では「Cassava」Windows向けの無料ソフトで編集しています。)
Excelで編集後に、csv形式のファイルとして保存する場合は
・名前をつけて保存(ファイル > 名前をつけて保存)
・ファイルの種類 ボックスの一覧から「CSV(カンマ区切り)を選択し保存
参考:
ブックをテキスト形式 (.txt または .csv) で保存する | Microsoft サポート
で保存できます。
FIMデータの入力項目と番号 – Excelなどで編集
以下の項目を、Excelなどで編集することでオリジナルFIM予測AIが作れます。
・id:順番に番号をふる
・sex – 性別:1男性・2女性
・age – 年齢:年齢をそのまま
・disease- 疾患情報(今回の主疾患):1 骨関節疾患・2 脳血管疾患・3 廃用症候群・4 その他
・pre_hospitalization_status – 病前の生活状態:1自立・2要支援1・3要支援2・4要介護1・5要介護2・6要介護3・7要介護4・8要介護5
・days – 発症からの経過日数:1 1週間・2 2週間・3 3週間・4 4週間・5 5週間・6 6週間・7 7週間・8 8週間・9 9週間以上
・family – 家族構成:1独居・2日中独居・3同居・4その他
・helper – 主要介護者の有無:0なし・1あり
・motivation – リハ意欲:1とてもある・2少しある・3あまりない・4全くない
・meal – 食事:FIM得点1〜7
・hygienic – 整容:FIM得点1〜7
・wipingClean – 清拭:FIM得点1〜7
・upperBodyDressing – 更衣上半身::FIM得点1〜7
・lowerBodyDressing – 更衣下半身:FIM得点1〜7
・toiletAction – トイレ動作:FIM得点1〜7
・urinationControl – 排尿管理:FIM得点1〜7
・defecationControl – 排便管理:FIM得点1〜7
・bedsChairsWheelchairs – ベッド・椅子・車椅子移乗:FIM得点1〜7
・toilet – トイレ移乗:FIM得点1〜7
・bathShower – 浴槽・シャワー移乗:FIM得点1〜7
・walkingWheelchair – 歩行・車椅子:FIM得点1〜7
・stairs – 階段:FIM得点1〜7
・understanding – 理解:FIM得点1〜7
・expression – 表出:FIM得点1〜7
・socialCommunication – 社会的交流:FIM得点1〜7
・problemSolving – 問題解決:FIM得点1〜7
・memory – 記憶:FIM得点1〜7
・discharge – 自宅退院:0 自宅退院できず・1 自宅退院
・〜_after_1M – 1ヶ月後のFIM得点1〜7
・〜_after_2M – 2ヶ月後のFIM得点1〜7
エクセルなどでcsvファイルを編集後、csv形式のファイルとして保存する際には、
・1行目の名前がつけられている項目の行を削除(idなどのローマ字が入力されている行の削除)
して、数字だけのデータにした状態で保存します。
今回は「fim_data.csv」というファイル名で保存したものを使って解説をしていきます。
オリジナルデータをfim_db.sqlite3に入れる
次に、csvファイルをSQLite3の「fim_db.sqlite3」にインポートします。(データをfim_db.sqlite3に入れます)
Visual Studio Codeで、「portfolio_predict_fim-master」のフォルダを開いた状態で、ターミナルで以下のコードを実行します。
以下のコードを順番に実行します。
①「fim_db.sqlite3」に入ります。
実行コード:(コードを入力後に「enter」キーを押します)
sqlite3 fim_db.sqlite3
②「fim_data」のテーブル内にあるサンプルデータを削除します。
実行コード:(コードを入力後に「enter」キーを押します)
delete from fim_data;
③ csvモードにします。
実行コード:(コードを入力後に「enter」キーを押します)
.mode csv
④ csvファイルをインポートします。今回は「fim_data.csv」というオリジナルデータセットを、「fim_db.sqlite3」内のテーブル「fim_data」に入れます。
実行コード:(コードを入力後に「enter」キーを押します)
.import '¥c:¥Users¥Windowsのユーザー名¥Desktop¥fim_data.csv' fim_data
(「.import csv_file_path table_name」でインポート。今回は、「.import 」の後に、半角英数でスペースを空けた状態でデスクトップ画面にある「fim_data.csv」というcsvファイルをドラッグ&ドロップしてファイルを認識させています。そのままではエラーになるようでしたので、インポートするファイルのパスなど全体を「'」で囲ってあります)
データベースの特定のテーブルの中身を確認したい場合は
実行コード:(コードを入力後に「enter」キーを押します)
select * from table名;
(select * from fim_data;)
で確認できます。
また、データベースの編集を終了する場合は
実行コード:(コードを入力後に「enter」キーを押します)
.exit
を実行します。
FIM予測AIをオリジナルデータで学習させる
次に、インポートしたオリジナルデータセットで学習させます。
① まずは、「djangoai」の仮想環境に入ります(仮想環境を起動します)。
実行コード:(コードを入力後に「enter」キーを押します)
djangoai\Scripts\activate
* 上記のコードをコピー&ペーストするか、そのままターミナルに「activate」(portfolio_predict_fim-master > djangoai > bin > activate)というファイルをドラッグ&ドロップする方法でもできます。
ターミナルの表示が
(djangoai)〜
に変わります。
②「python create_df_pickle.py」(predict_fim_app > create_model > src)を実行します。
実行コード:(コードを入力後に「enter」キーを押します)
python ¥c:¥Users¥Windowsのユーザー名¥Desktop¥portfolio_predict_fim-master¥predict_fim_app¥create_model¥src¥create_df_pickle.py
* 「python」と入力後、半角スペースを空けた状態で、そのままターミナルに「create_df_pickle.py」(predict_fim_app > create_model > src > create_df_pickle.py)というファイルをドラッグ&ドロップする方法で実行します。
コードが実行されると、「data」(predict_fim_app > create_model > data)内に「df.pickle」というファイルが作成されます。
③「train.py」(predict_fim_app > create_model > src > train.py)を実行します。
実行コード:(コードを入力後に「enter」キーを押します)
python ¥c:¥Users¥Windowsのユーザー名¥Desktop¥portfolio_predict_fim-master¥predict_fim_app¥create_model¥src¥train.py
* 「python」と入力後、半角スペースを空けた状態で、そのままターミナルに「train.py」(predict_fim_app > create_model > src > train.py)というファイルをドラッグ&ドロップする方法で実行します。
上記を実行すると、「trained_models」(predict_fim_app > create_model > src > trained_models)内の学習済モデルのデータが更新されます。
これで、オリジナルデータセットを使ってFIM予測AIを学習させることができました。
機械学習・人工知能のリハビリテーション応用

機械学習とFIM予測関連研究の動向は?
2020年8月に CiNii(サイニィ – NII学術情報ナビゲータ) で
キーワード
:機械学習 リハビリ fim
と、日本語の論文を検索してみると「1件」の論文がヒットしました。
論文名
:機械学習を用いた急性期脳出血症例におけるFIM利得予測キーワード
:脳出血, 機能的自立度評価法論文情報
:人工知能学会全国大会論文集 第34回全国大会(2020) セッションID: 1C5-GS-13-04 開催日 2020/06/09 – 2020/06/12論文リンク(J-STAGEにリンクします)
:https://www.jstage.jst.go.jp/article/pjsai/JSAI2020/0/JSAI2020_1C5GS1304/_article/-char/ja
* 無料で全文ダウンロード可能でした
急性期の脳出血症例のFIM利得を機械学習で予測する試みの論文のようです。機械学習モデルは、ニューラルネットワークと勾配ブースティング木のアンサンブル学習のようです。
その他に、 PubMed(パプメド) で
キーワード
:rehabilitation machine learning fim
と、英語の論文を探してみると「3件」の論文がヒットしました。
論文名
:Predicting Functional Independence Measure Scores During Rehabilitation with Wearable Inertial Sensorsキーワード
:machine learning; prediction; rehabilitation monitoring; signal processing; wearable sensors.論文情報
:IEEE Access. 2015; 3: 1350–1366.論文リンク(Pubmedにリンクします)
:https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4819996/
* 無料で全文ダウンロード可能でした
ウェアラブルセンサー(慣性計測装置)のデータとFIM(退院時FIMスコア)の状態を予測した研究のようです。
機械学習のモデルはサポートベクターマシーン(epsilon support vector machine:ε-SVM)のようです。
* ε(イプシロン):不感損失関数
* 線形イプシロン不感応 SVM(ε-SVM)回帰
論文名
:Predicting Motor and Cognitive Improvement Through Machine Learning Algorithm in Human Subject that Underwent a Rehabilitation Treatment in the Early Stage of Strokeキーワード
:Inflammation; Predictive values; Rehabilitation; SVM regression and FIM; Stroke.論文情報
:J Stroke Cerebrovasc Dis. 2018 Nov;27(11):2962-2972.論文リンク(Pubmedにリンクします)
:https://pubmed.ncbi.nlm.nih.gov/30077601/
* アブストラクトは無料で閲覧可能でした
急性期脳卒中罹患者に対して、機械学習モデルの1つ、サポートベクターマシーン(Support Vector Machines :SVMs)でFIMなどを予測した研究のようです。
論文名
:Machine-learning prediction of self-care activity by grip strengths of both hands in poststroke hemiplegiaキーワード
:activities of daily living, grip strength, rehabilitation, self-care, stroke論文情報
:Medicine: March 2020 – Volume 99 – Issue 11 – p e19512論文リンク(Pubmedにリンクします)
:https://pubmed.ncbi.nlm.nih.gov/32176098/
* 無料で全文ダウンロード可能でした
急性期脳卒中罹患者に対して、機械学習のモデルの1つ、非線形サポートベクターマシーン(non-linear support vector machine)で握力とセルフケア(FIM項目)の状態を予測した日本の方による研究のようです。
少しずつではありますが機械学習分野で使われるモデルを意識した研究が出始めてきているようです。
おそらくこれからの分野なのでしょうね。
今(2020年)、研究論文を発表すればこの分野のパイオニアになれそうです。
【追記:2021年7月25日】
日本人の著者による、機械学習のモデルのディープラーニング(深層学習)を用いて回復期病棟でFIM予測をした論文も公表されたようです。
論文名
:Deep Learning-Based Functional Independence Measure Score Prediction After Stroke in Kaifukuki (Convalescent) Rehabilitation Ward Annexed to Acute Care Hospitalキーワード
:artificial intelligence (ai), deep learning (dl), functional independent measure (fim), kaifukuki (convalescent) rehabilitation ward (krw), stroke, prediction model, prediction one, sony network communications inc. japan論文情報
:Cureus:July 2021 13(7):e16588論文リンク(ResarchGateにリンクします)
:https://www.researchgate.net/publication/353414272_Deep_Learning-Based_Functional_Independence_Measure_Score_Prediction_After_Stroke_in_Kaifukuki_Convalescent_Rehabilitation_Ward_Annexed_to_Acute_Care_Hospital
* 無料で全文ダウンロード可能でした
これまでのFIMの予測モデル関連の研究論文の把握や、どのような因子(特徴量)が予測モデルに影響を与える可能性があるのかなどを把握する上で参考になるのではないかと思います。
論文では、ソニーネットワークコミュニケーションズ株式会社(Sony Network Communications Inc)により提供されている「Prediction One」(プレディクション ワン)を活用して予測モデルを作成しているようです。
ディープラーニングというと、
・学習をさせる際のパソコンのスペック(GPU・・・)
・PythonやKerasなどの関連ライブラリの基礎知識の習得
などがネックになり、研究を断念される方もいるのではないかと思います。
2021年7月に確認時点では、「Prediction One」は、クラウド版・デスクトップ版が公開されているようですが、クラウド版の場合は、自分のパソコンのスペックを気にせずにできるのでありがたいですね。
今後、上記のようなGUIツールを活用することで、リハビリ専門家によるAI研究が当たり前になる日が来ることを楽しみにしています。
ただ、病院などに勤務されているリハビリ臨床家が、自分の思いだけで気軽に開始するには、年間費用面が・・・・まだまだ課題になりそうですね。
以下は、著者(@cuty_katsuki | Twitter)による「Prediction One」に対するコメントです。
紹介してくださりありがとうございます。嬉しいです。このPrediction Oneというソフトのいいところは、データさえあればプラグラミングが不要でかんたん、というところです。ぜひ今後ともよろしくお願いします。
— きゅーてぃー勝木 cuty KATSKI シンガーソングライター YouTuber (@cuty_katsuki) July 26, 2021
「データさえあればプログラミング不要でかんたん」とのことです。
病院や介護施設・福祉施設などに勤務されているリハビリ臨床家の中には、日々の業務をこなすだけで手一杯の方もいるのではないかと思いますが、「Prediction One」をはじめとした何かしらのツールで、データを活用できると、見える世界が変わってくるのかもしれませんね。
FIM予測AIアプリの臨床研究案・課題・応用の可能性
上述の機械学習を応用した国内外のFIM予測関連研究と比較した場合、この記事で、使い方をまとめさせていただいている
・回復期病院を想定したFIM予測AIアプリ
tomoyasu-sano/portfolio_predict_fim | GitHub
https://github.com/tomoyasu-sano/portfolio_predict_fim
開発者の方によるデモ | FIM予測AI
* 2023年1月時点では開発者の方によるデモがなくなっているようでした
の大きな特徴は
・アプリ化されている
点ではないかと思います。
いくら素晴らしい機械学習の学習モデルが出来たとしても、臨床現場で気軽に使えなくては、機械学習の恩恵をリハビリ専門家が感じる機会は少ないのではないかと思います。
機械学習分野に関して、現状の個人の学習で分かる範囲で、公開してくださっているコードを拝読した感じでは、実際に研究する場合や実践でより良い性能のAIとして使うためには
・学習の際に使う特徴量の選定(他の因子の影響は?)
・LightGBMのパラメータの調整(デフォルトのコードでは「num_boost_round=100:100ラウンドまで学習」)
などについて、AIに学習させる中で検討する必要はあるのではないかと思いました。
(ただ、個人的には、ここまでの状態のコードを公開してくださり、感謝しています。)
続いては、回復期病院を想定したFIM予測AIアプリを活用した研究を検討中の方もいるのではないかと思いますので、以下に、簡単ではありますが運営者なりの研究案などをまとめておきたいと思います。
【FIM予測AIアプリの機械学習モデル自体の課題と研究】
・研究テーマ例
– 機械学習を用いたFIM・自宅退院予測
:まずは性能がどうかの検証。セラピスト間のFIMの評価方法の統一や、機械学習モデルの検証が必要かもしれません。
・研究テーマ例
– 機械学習を用いた回復期(または急性期)xx症例におけるFIM予測AIアプリの有用性
:AIの性能を検証する際に、脳血管障害・整形外科疾患・廃用症候群の大きな括りではなくて、細分化する必要もあるのかもしれません。
・研究テーマ例
– セラピスト vs AI:回復期リハビリテーション病棟における自宅退院可能性の予測
:入院初期のFIM・各種属性(疾患・個人因子・環境因子など)から、自宅退院の可能性を予測します。セラピストによる予測と、AIによる自宅退院の予測(確率)を比較。AIの方が精度が良かった場合は、機械学習モデルなどの詳細を考察。AIの精度が悪かった場合は、課題を考察。
【FIM予測AIアプリを臨床現場で活用する研究】
・研究テーマ例
– AIアプリ導入・活用の意識調査
:現状では、臨床現場で活用できるようなAIアプリの存在が認知されていない可能性も否めないのではないかと思います。また、様々な課題も見えてくるのではないかと思います。
・研究テーマ例
– FIM予測AIアプリ活用によるセラピストの変化
:FIM予測AIの導入前後のセラピストの意識変化などの研究。アンケート調査内容を工夫することで様々な研究ができるのではないかと思います。
・研究テーマ例
– FIM予測AIアプリ活用による多職種連携の変化
:FIM予測AIの導入前後の多職種連携の意識変化などの研究。性能の良いAIであれば、改善が予測される項目に関して、現状を多職種と情報共有・協議する際の一助になるのではないかと思います。
【FIM予測AIアプリの応用の可能性】
Python機械学習プログラミング・Djangoによるウェブアプリ開発に詳しい方であれば(おそらくですが・・・)
・回復期病院を想定したFIM予測AIアプリ
を活用して様々な用途のリハビリ系AIアプリに応用できるのではないかと思います。
応用例
– 急性期版のFIM・自宅退院予測AIアプリ
応用例
– 脳卒中片麻痺者の歩行予測AIアプリ
応用例
– 脳卒中片麻痺者の麻痺改善予測AIアプリ
応用例
– 失語症の改善予測AIアプリ
応用例
– 誤嚥性肺炎予測AIアプリ
応用例
– 転倒予測AIアプリ
今後、機械学習分野の知識・技術が活用される中で、医療・リハビリテーション分野でも性能の高いAIを作れることが認知・認識されるようになることで、急性期・回復期・生活期(訪問リハビリテーションなど)を跨いだ、長期的な変化に関心をもたれる方も増えてくるのではないかと思います。
医療データの利活用に関する指針が、世界的にどうなっていくのかはわかりませんが、特定の病院・施設だけの研究のみならず、勤めている病院・施設外との共同研究により、急性期病院(回復期病院・訪問リハビリ・他施設など)に勤めているだけではわからなかった、様々なことが可視化されてくるのではないかと思います。
Pythonプログラミング・機械学習モデルLightGBMについて
Djangoについて:Pythonでウェブアプリ開発
余裕があれば… 関連事項などをまとめていきたいと思います。ジャンゴと読むようです。
簡単にまとめると、プログラミング言語Pythonでウェブアプリが開発できる仕組みのようです。
LightGBMについて:機械学習モデル
余裕があれば… 関連事項などをまとめていきたいと思います。ライトジービーエムと読むようです。
LightGBMはMicrosoftから公開されている機械学習モデルのようです。
このページの情報をもとに、ウェブAIアプリを動かす体験を経験することで、リハビリテーション領域の機械学習の応用に興味を持ってくださる方が一人でも増えるようでしたら嬉しいです。
まだまだ敷居は高いですが、プログラミングがある程度分かったほうが、色々と臨床や研究で試せて、面白そうですね・・・
今回は、分かる範囲の解説になりましたが、長文の閲覧ありがとうございました。
まだまだ、機械学習分野やプログラミングに関する知識は未熟ですが、少しずつ学習していきたいと思います。
公開してくださっているコードは、LightGBMの最小設定でAIの学習がされているようです。
その他の因子を追加したり、実践で活用できる、より性能のよいAIを作成するためには、
・機械学習(LightGBMなど各種モデル)やPythonプログラミング・データ分析系ライブラリを学ぶ
必要があるのではないかと思います。
また、FIM予測AIの予測結果ページを確認してみると、ありがたいことに、開発者の方が共同研究をしてくださる病院・施設の方などを募集されているようでした。
2020年8月に確認時点では、連絡や質問等はTwitterで受け付けてくださっているようです。興味がある方は、開発者の方にコンタクトしてみてください。
FIM予測AIアプリの開発者のTwitterアカウント
:@AnytimesSano | Twitter
今後、病院・施設に勤務されている臨床家の共同研究者が現れることで、よりよいAIアプリが開発される日を楽しみにしています。